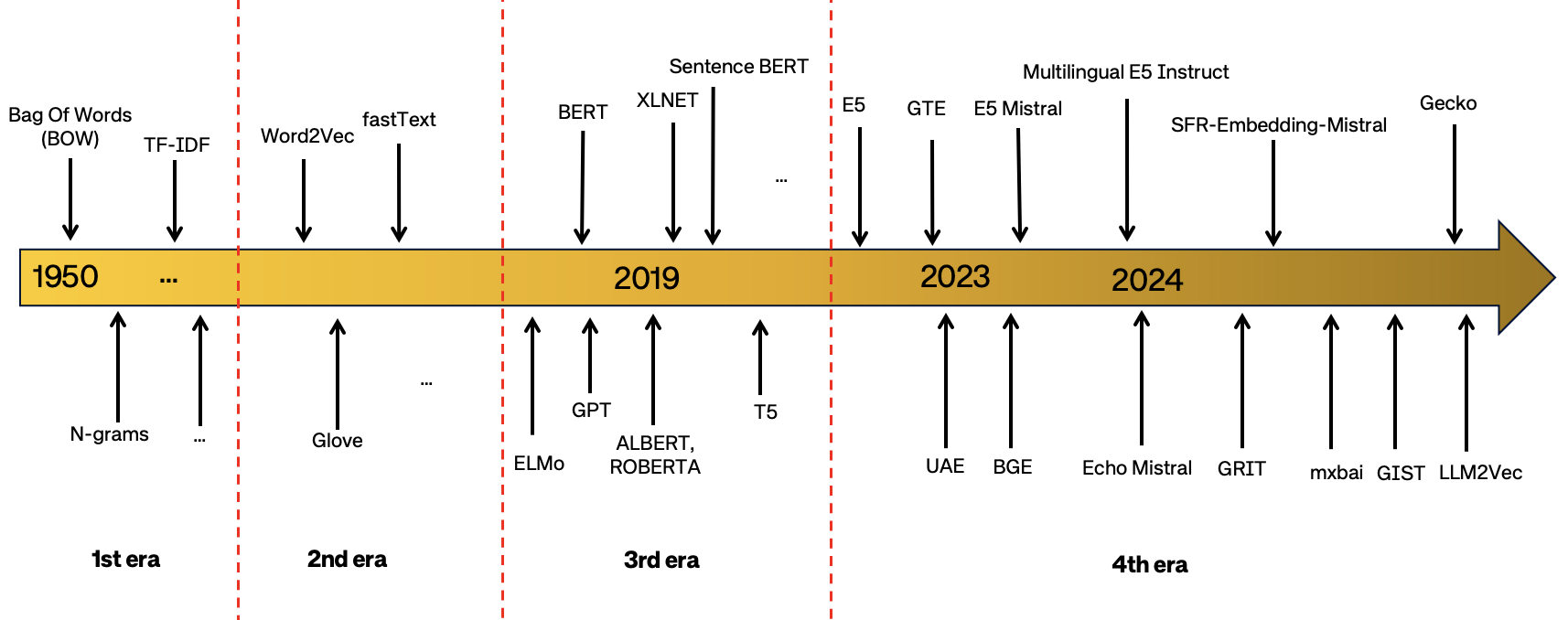
Embeddings and text representations
Embeddings are dense, low-dimensional vector representations of data, such as words, images, or entities, that capture their semantic or contextual meaning in a continuous space. They are used to convert high-dimensional or categorical data into a format suitable for computational models, enabling efficient similarity comparisons and feature extraction.
Resources
- Text Embeddings: Comprehensive Guide | by Mariya Mansurova | Towards Data Science
- An intuitive introduction to text embeddings - Stack Overflow
Bag of words
- A commonly used model in methods of Text Classification. As part of the BOW model, a piece of text (sentence or a document) is represented as a bag or multiset of words, disregarding grammar and even word order and the frequency or occurrence of each word is used as a feature for training a classifier.
- BoW is different from Word2vec, which we’ll cover next. The main difference is that Word2vec produces one vector per word, whereas BoW produces one number (a wordcount). Word2vec is great for digging into documents and identifying content and subsets of content. Its vectors represent each word’s context, the ngrams of which it is a part. BoW is good for classifying documents as a whole.
TF–IDF
- https://en.wikipedia.org/wiki/Tf–idf - Term Frequency-Inverse Document Frequency
- Numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus.
- The tf-idf value increases proportionally to the number of times a word appears in the document, but is often offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general.
Word embeddings
- Word embedding - Wikipedia
- Word embedding is a way of representing words as vectors. The aim of word embedding is to redefine the high dimensional word features into low dimensional feature vectors by preserving the contextual similarity in the corpus. They are widely used in deep learning models such as Convolutional Neural Networks and Recurrent Neural Networks.
- #PAPER Word2Vec: Distributed Representations of Words and Phrases and their Compositionality (Mikolov 2013)
- https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
- Skip-gram model with negative sampling
- https://code.google.com/archive/p/word2vec/
- Paper explained
- http://p.migdal.pl/2017/01/06/king-man-woman-queen-why.html
- http://multithreaded.stitchfix.com/blog/2017/10/18/stop-using-word2vec/
- #PAPER Distributed representations of sentences and documents (Le 2014)
- #PAPER GloVe: Global Vectors for Word Representation (Pennington 2014)
- Glove - unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space.
- #PAPER sense2vec - A Fast and Accurate Method for Word Sense Disambiguation In Neural Word Embeddings (Trask 2015)
- #PAPER Enriching Word Vectors with Subword Information (Bojanowski 2017)
Transformer and LLM-based embeddings
- Training and Finetuning Embedding Models with Sentence Transformers v3
- Introduction to Text Embeddings
Code
- #CODE Sentence-transformers - This framework provides an easy method to compute dense vector representations for sentences, paragraphs, and images
Courses
References
- #PAPER SGPT: GPT Sentence Embeddings for Semantic Search (2022)
- #PAPER Improving embedding with contrastive fine-tuning on small datasets with expert-augmented scores (2024)
- #PAPER LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders (2024)
- #PAPER #REVIEW Recent advances in text embedding: A Comprehensive Review of Top-Performing Methods on the MTEB Benchmark (2024)